
Crowdsourced Data Labelling Platform for AI/ML Training Data
Build with Node.js, Express, MongoDB
Login credentials for Demo
| User Type | Password | |
|---|---|---|
| Admin | admin@admin.com | admin |
| Client | client1@client.com | client1 |
| Labeller | john@john.com | john |
Introduction
Having just learnt the basics of building full-stack web applications, we were given one week to develop and deploy an app using the technologies we were taught. Namely, Node.js, Express, MongoDB in the backend, with EJS as the templating language for client views.
We were also given free rein on the type of application to build, as long as there were login capabilities and usage of a database.
Initially, I brainstormed several ideas which revolved around the common web app use cases like E-Commerce, Forums/Boards, Calendar/To-Do lists, etc. However, these use cases were pretty overused and would be trivial to replicate since there were many examples floating around.
Instead of thinking about the common types of web applications, I then decided to consider real business problems that I have encountered, and attempt an MVP that addresses a simplified version of the problem.
Motivation
I landed on Labellr, a data labelling platform to help data scientists crowdsource manual labels for their AI/ML training data. One of the many bottlenecks faced by data scientists is obtaining sufficient and accurate labelled training data as input into their models.
Even though there are pre-labelled data readily available online, these labels may not be suited for the specific context in which the data scientists are trying to model. (e.g. “this vacuum cleaner sucks” - would this be a positive or negative sentiment?)
Labellr aims to provide a platform for crowdsourcing labellers to not only help label training data, but allow for users/data scientists to select different demographics to help label the data in specific contexts.
I was excited about this since it was a data-related problem that I have encountered and attempted to solve (hackily) before.
It was also a good opportunity to design a system and data model for a typical crowdsourcing platform which could transfer easily to other types of similar business problems.
Key Features
Here are some of the key defining features of Labellr.
User Types
- Labellers
- Users who can sign up, login and take on any available workflows that are available
- Clients
- Data Scientists or ML Engineers who have training data that needs to be manually labelled by humans
- Clients can create labelling workflows, bulk upload training data to be labelled, view labelling stats and download results in a csv
- Admin
- Superuser with admin privileges to create, update, delete workflows and users
- View overall stats of the Labellr instance
Labelling Process
Labellr allows clients to upload text based data and request for either Sentiment or Topic labelling.
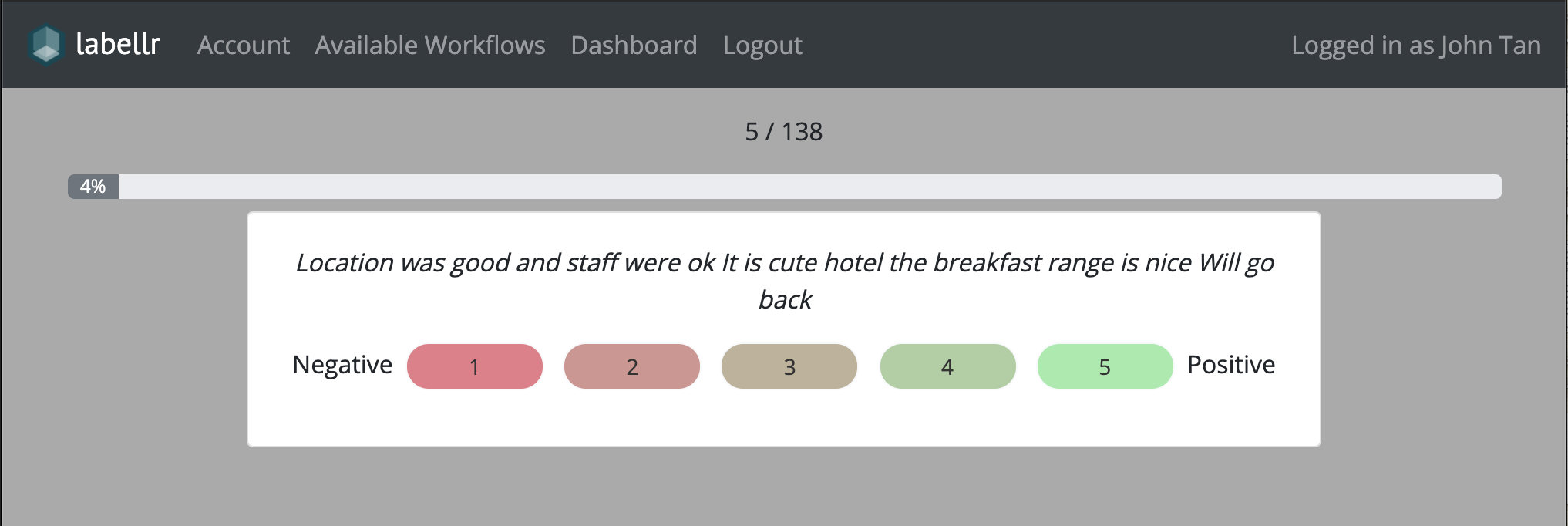
Sentiment labels range from 1 (very negative) to 5 (very positive), with 3 being neutral.
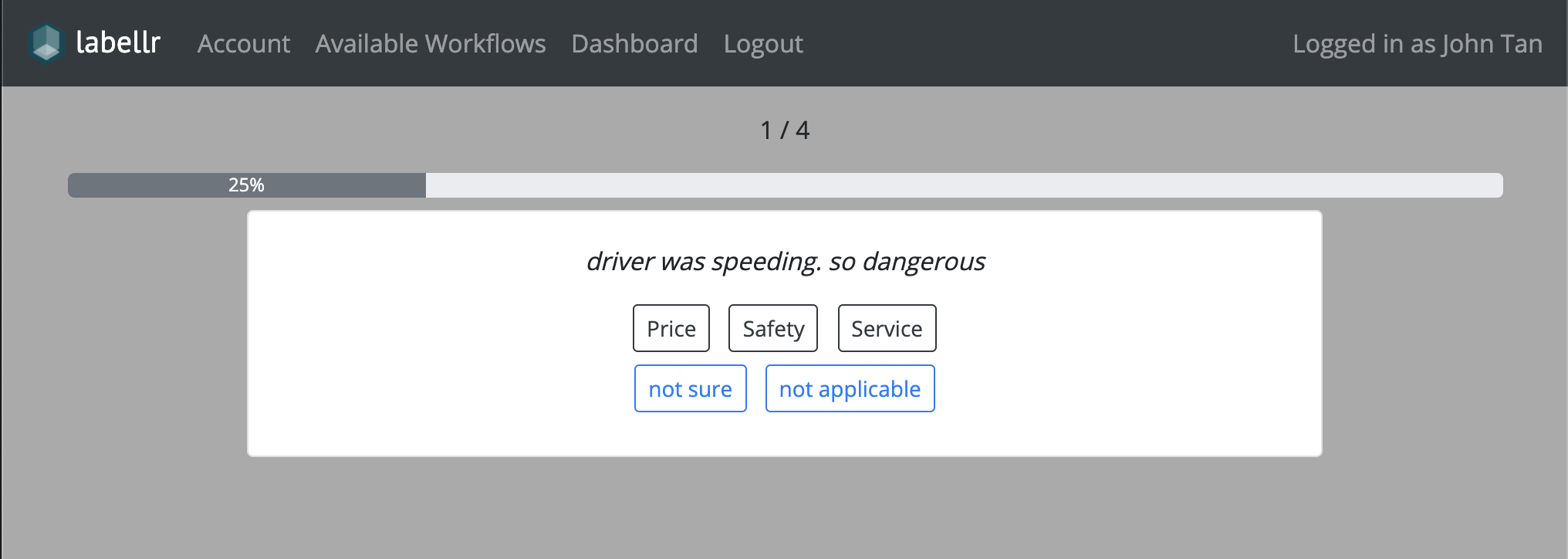
Topic labels are predefined by the client at the creation of the workflow. The labels Not Sure and Not Applicable are automatically included as topic labels for users to select if the text content is unclear or irrelevant to the existing options.
During the labelling process, the text is shown one at a time (instead of a list), to enable the labeller to focus on the text data on hand, and not be distracted or affected by other text content.
Labellers can exit the workflow anytime and return to it later. Their progress will be automatically saved.
Labelling Results
Clients are able to see updated stats about the workflow they created. Information about the number of labellers, number of labelled data points and number of useful data labels is shown on the workflow details page.
Clients can also download the raw results of the labelling as a csv at any time. Client (or Admin) can close the workflow and prevent any more labels once the results are satisfactory.
Project Retrospective
I was pretty satisfied with the final product given the original objective was to have an MVP within 5 days that solves a simplified version of the data annotation problem.
What definitely helped was that I worked in clearly defined sprints (4 to 5 hours per sprint), with specific features and user stories to work on for each sprint. During development, inevitably, new ideas/experiments for features would pop up in my head, but in order to keep myself focused, I threw these ideas into the backlog and only focused on my current sprint. I also ensured that the end of the each sprint resulted in a mini-MVP that would be minimally functioning and have been manually tested.
On hindsight, there were definitely some things that could be further improved. For instance, using a Relational DB such as postgreSQL would fit the data model better since there were clear and limited relationships between each data entity in the application. Queries to the database especially regarding labelling stats would have been more intuitive.
The strategy for selecting text content to display to the labeller could definitely have been further improved. One way is to first randomize the order for each labeller and only select data points do not yet have a decisive label. Statistical adjusments should also be made based on the individual labelling behaviour - i.e. Specifcally for sentiment labelling, a baseline should be determined for each user and have their labels adjusted relative to that baseline.
Further Work
Given more time, these are some of the additional features that I would prioritize.
- Allow clients to specify demographic requirements of labellers (e.g. Age, Gender, Country of Residence/Origin)
- Allow labelling and annotation of images
- APIs for clients to upload/download the relevant datasets and connect to DBs
- Gamify the labelling process to further motivate the labeller
Comments